Информация, доступная нам через "поисковики", - лишь малая часть того, что на самом деле находится в сети. Чтобы открыть для себя весь необъятный мир вэба, нужно знать, как искать.
Чаще всего, когда нам необходима какая-либо информация в интернете, мы прибегаем к помощи популярных информационно-поисковых систем (ИПС), таких как Google, Yahoo!, AltaVista или "Яндекс". Однако, как оказалось, кроме видимой для "поисковиков" части вэб-пространства существует огромное количество страниц, которые ими не охватываются.
Подобные ресурсы имеют собственное название - "скрытый" вэб (deep web), которое обозначает источники, недоступные для обычных поисковых систем. Однако к таким вэб-страничкам все же можно добраться и найти на них много полезной информации.
В 2000 году американская компания BrightPlanet с помощью программы LexiBot осуществила сканирование в сети некоторых динамических вэб-страниц, формируемых из баз данных.
Результаты были ошеломляющими - неопознанных ресурсов в интернете оказалось в сотни раз больше, чем доступных сегодня традиционным информационно-поисковым системам. То есть 10 миллиардов вэб-страниц - это лишь видимая крупица Глобальной паутины. В результате исследований также выявилось немало интересных особенностей "скрытых" вэб-страниц. Например, оказалось, что они в среднем на 27 % компактней страниц из видимой части интернета.
Невидимыми ресурсы для ИПС оказались по причине алгоритмов работы популярных роботов-индексаторов. Такие программы, как правило, посещают вэб-страницы по известным заранее адресам, анализируют их содержание и выделяют гиперссылки, идущие от них. Обычно, обработав текущую страницу, выделив ключевые слова и некоторые поля, робот переходит по адресам, найденным на ней. Затем система опять сканирует последующие страницы и выделяет новые адреса. Однако как только робот определяет, что он обращается к динамической странице, его работа приостанавливается. Ведь для получения осмысленного ответа из баз данных требуется соответствующий запрос, а большинству из роботов чужды элементы интеллекта (даже искусственного).
То есть "скрытый" вэб формируется в первую очередь из содержимого онлайновых баз данных. Сюда следует добавить и быстро обновляемые ресурсы, так называемые динамические. К ним относятся новости, конференции, онлайновые журналы и др. Конечно, есть и "острова" Глобальной паутины, на которые не ведут никакие гиперссылки и от которых гиперссылки не исходят. Защищенные паролями вэб-сайты также попадают в категорию "скрытого" интернета.
О материалах этих сайтов большинство пользователей никогда не узнают с помощью стандартных поисковых систем. Однако относительное количество таких ресурсов невелико. По мнению ученых, среди крупнейших сайтов "скрытого" вэба платными являются только 10 % ресурсов.
В свое время исследователи BrightPlanet определили более десятка разновидностей "скрытых" вэб-ресурсов, относящихся к классу онлайновых баз данных. В списке оказались как традиционные базы данных (патенты, медицина и финансы), так и публичные ресурсы - объявления о поиске работы, чаты, библиотеки, справочники. Ученые также причислили к "скрытым" ресурсам и специализированные поисковые системы, которые обслуживают определенные отрасли или рынки. При этом базы данных таких ИПС не включаются в каталоги глобальных поисковых служб.
К "невидимой" части сети также относятся многочисленные системы интерактивного взаимодействия с пользователями - помощи, консультации, обучения, требующие участия людей для формирования динамических ответов от серверов. В ней также находится и закрытая (полностью или частично) информация, доступная пользователям сети только с определенных адресов, групп адресов, а иногда городов и стран.
Например, для нашего пользователя наверняка "скрытой" можно признать большую часть гигантского китайского сегмента интернета.
Так, малоизвестный в Европе и Америке китайский поисковый портал Baidu (www.baidu.com) в 2004 году опередил Google по объему трафика, став четвертым в мире вэб-ресурсом по этому показателю. Другая китайская поисковая система 3721.com (http://www.3721.com/) заняла седьмое место в списке самых посещаемых ИПС.
В ноябре 1999 года Андрей Бродер (Andrei Broder) совместно с другими учеными из компаний AltaVista, IBM и Compaq математически описали карту ресурсов и гиперсвязей интернета. Исследователи опровергли расхожее мнение, будто интернет - это единое густое пространство. Проследив с помощью поискового механизма AltaVista свыше 200 млн. вэб-страниц и несколько миллиардов ссылок, ученые построили ориентированный граф с топологией "галстук-бабочка" (Bow Tie), которая, по их мнению, соответствует структуре вэб-пространства (см. рис 1). У ученых получилась модель связности, охватывающая более 90 % исследованных вэб-страниц в сети:
- центральное ядро (SCC) составляют ресурсы, взаимосвязанные так тесно, что, следуя гиперссылкам, из любой из них, в конечном счете, можно попасть на другую страницу. Они занимают порядка 28 % вэб-страниц интернета;
- отправные вэб-страницы (IN) содержат гиперссылки, которые, в конечном счете, ведут к ядру, но из ядра к ним попасть нельзя. Таких страниц 22 % в сети;
- оконечные страницы (OUT) составляют 22 % всех ресурсов. На них можно попасть по ссылкам из ядра, но нельзя вернуться обратно;
- отростки (Tendrils) - области вэб-страниц, которые оказались полностью изолированы от центрального ядра, но на них можно попасть из областей IN и OUT. Эти ресурсы составляют 22 %;
- несвязанные узлы (всего 6 %) представляют собой островки без связи с другими вэб-страницами.
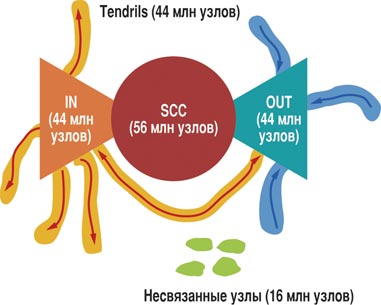
Рис 1. Структура вэб-пространства, по мнению ученых, представляет собой топологию галстук-бабочка (Bow Tie)
Как это ни парадоксально, но к скрытой части сети порой относятся и крупнейшие мировые службы информационного поиска. Например, портал
Dialog (
http://www.dialog.com), который сегодня принадлежит корпорации Thomson (США) - одной из всемирных лидеров в предоставлении информационных сервисов в области бизнеса, науки, финансов, законодательства и др. На
Dialog находится более 900 баз данных, из которых пользователи ежемесячно просматривают порядка 17 миллионов страниц документов с различной информацией. При этом
Thomson определяют эти ресурсы как часть "скрытого" вэба, заявляя, что они содержат полезной (не дублирующейся) информации в 500 раз больше, чем доступно с помощью традиционных информационно-поисковых систем.
В "скрытом" интернете также существует множество альтернатив базам данных типа Dialog. Среди них, например, сайт
http://www.10kwizard.com/, предлагающий доступ к полным текстам корпоративных документов, хранящихся в Комиссии США по ценным бумагам и биржам. Другой ресурс - Educator's Reference Desk (
http://www.askeric.org/) содержит свыше двух тысяч учебных планов, несколько тысяч ссылок на образовательные документы. С этого сайта обеспечивается доступ к базе данных
ERIC - крупнейшему источнику информации по проблемам образования, а также к полнотекстовым дайджестам, составляемым экспертами. Австралийский ресурс
Nuclear Explosions Database ((
http://www.ga.gov.au/oracle/nukexp_query.html) содержит базу данных по географии.
Для работы с системой достаточно перейти в режим Online Tools, после чего будет представлен список баз данных и карт.
Вэб-портал PubMed (
www.ncbi.nlm.nih.gov/entrez/query.fcgi) обеспечивает доступ к более чем 14 миллионов ссылок на материалы американской Национальной библиотеки по медицине (National Library of Medicine), включая ссылки на полные тексты статей и информационные ресурсы. С портала обеспечивается также доступ к глобальной поисковой системе
NCBI (
http://www.ncbi.nlm.nih.gov/), охватывающей базы данных по естествознанию и медицине.
Приведем пример еще одной, весьма интересной "скрытой" базы данных в сети. Так, корпорация
ChoicePoint недавно предоставила сервис
AutoTrackXP (
http://www.autotrackxp.com/), вошедший в список двадцати крупнейших "скрытых" сайтов мира (по рейтингу BrightPlanet).
AutoTrackXP представляет собой базу данных объемом 30 терабайт, охватывающую практически все аспекты гражданской жизни США. Эта база данных содержит информацию практически о каждом гражданине США. Например, чтобы определить, не завладел ли человек чужими документами, на системе организован платный сервис
ProCheck, позволяющий сопоставить информацию из различных государственных каталогов.
Парадоксально, но как ресурсы "скрытого" вэба можно рассматривать и некоторые архивы общедоступного вэб-пространства. Например, такой архив
Internet Archive компании
Alexa (
http://www.ale-xa.com/) содержит базы данных объемом более 500 терабайт. Новые страницы в настоящее время попадают в хранилище со скоростью 1 терабайт в день.
Технология хранилища Alexa включает ряд современных средств управления гигантским контентом. Например, с ее помощью выполняется кластеризация вэб-ресурсов, то есть формирование коллекций документов, близких по тематикам. Особый интерес у пользователей Alexa вызывает сервис
"Машина времени" (Wayback Machine). Он позволяет восстанавливать документы, некогда опубликованные в интернете, но впоследствии удаленные.
Традиционная поисковая система чаще всего может назвать адрес базы данных, но не скажет, какие документы конкретно содержатся в ней. Типичный пример - информационно-поисковые системы по украинскому (
http://www.rada.gov.ua/) и российскому (
http://www.kodeks.ru/) законодательству. Тысячи документов из их баз данных становятся доступны только после входа в систему. При этом роботы стандартных ИПС не в состоянии проиндексировать контент подобных баз данных.
"Скрытый" вэб представляет собой гигантское хранилище документов, звуков, изображений, фильмов и др. Безусловно, если большая часть этой информации не доступна традиционным поисковым системам, то существует потребность в специальных инструментах для поиска "скрытого" контента.
Так, для поиска в "скрытой" сети (а именно в том ее сегменте, который составляют базы данных) сегодня уже существуют некоторые специализированные ресурсы. Среди них, например, система
Invisible Web (
http://www.invisible-web.net/) компании IntelliSeek. Сайт включает каталоги баз данных, большинство из которых не проиндексированы известными поисковыми системами.
При введении запроса этот механизм выдает ссылки на ресурсы, с помощью которых поиск необходимой информации станет наиболее оптимальным. На этом вэб-сайте также собраны коллекции ссылок на различные базы данных, среди которых содержится немало уникальных ресурсов, например, сборник выступлений и докладов известных политиков и бизнесменов.
Известным навигатором в "скрытом" интернете является и сайт
CompletePlanet (
http://www.completeplanet.com/) компании
BrightPlanet. Этот ресурс является крупнейшим каталогом, насчитывающим свыше 100 тыс. ссылок. Специальный метапоисковый пакет DeepQuery-Manager этой же компании обеспечивает поиск по 55 тыс. "скрытых" вэб-ресурсов.
Вэб-сайт Direct Search (
www.freepint.com/gary/direct.htm) также обеспечивает поиск в базах данных "скрытого" вэба. На сайте содержатся ссылки на лучшие ресурсы ценовой (
MySimon.com) и финансовой (
FinancialFind.com) информации, а также ссылки на ресурсы научно-популярных журналов и научных баз данных (
Biolinks.com).
В интернете есть и другие сайты-навигаторы, а также специализированные программы поиска. Например,
Infomine Multiple Database Search (
http://infomine.ucr.edu-/search.phtml) - поисковая система по университетским архивам, библиотекам и книгам;
Bubl Link (
http://www.bubl.ac.uk/link/) - каталог информационных сайтов, посвященных различным областям человеческой деятельности;
Amazon.com (
http://www.amazon.com/) - полнотекстовый поиск по содержанию всех книг.
Стоит отметить, что особенностью большинства ресурсов-невидимок является их узкая специализация. Поэтому роботы поисковых систем для "скрытого" вэба включают уникальные для каждого такого ресурса модули доступа к данным.
Информация, представленная в форматах, отличных от
HTML, для многих известных поисковых систем до последнего момента оказывалась недоступной. Однако сегодня ситуация меняется в лучшую сторону. Например, популярная система Google (
http://www.google.com/) уже обеспечивает поиск в документах, представленных в форматах
MS PowerPoint, DOC, RTF, PostScript и PDF, а также осуществляет преобразование этих файлов в текстовый формат. При этом поиск документов в разнообразных форматах доступен в этой системе как из режима расширенного поиска
(Advanced Search), так и из обычного поиска - достаточно использовать в запросе команду
filetype: (например, для файлов
PDF это будет
filetype:pdf).
Другая известная служба
Yahoo! (
http://www.yahoo.com/) также обеспечивает выдачу текстовых копий документов, размещенных в форматах
Word, Excel, PowerPoint, PDF, RSS/XML-фидов (новостных лент и блогов - "живых журналов"). В свою очередь, специализированная система
Gigablast (
http://www.gigablast.com/) предназначена исключительно для поиска по документам в форматах
Word, Excel и PDF. Она выдает по запросу кэшированные (архивные) копии документов в исходных форматах, при этом обеспечивает поиск и выдачу копий документов, которые были размещены в сети, но затем, возможно, удалены.
Ввиду роста количества веб-сайтов, использующих в своей работе информационные базы данных и различные динамические системы управления контентом, "скрытый" сегмент интернета растет очень интенсивно. При этом все меньшая часть информационных ресурсов становится доступной пользователям посредством традиционных поисковых механизмов.
Оказалось, что спасти ситуацию могут новые возможности унификации данных в интернете. Одним из первых проектов консорциума
W3C, занимающимся развитием Глобальной сети в этой области, стал "Семантический Вэб". Его основная идея заключается в организации данных, которая позволила бы вэб-серверам (с программами разных производителей) эффективно их использовать. В рамках проекта были разработаны спецификации метаязыка
XML, предусматривающие разделение средств визуализации и смыслового содержания. На основе
XML удается создавать различные форматы, специально предназначенные для организации коммуникации, как между персональными устройствами, так и между серверами. Так, например, для решения задачи интеграции новостной информации было создано несколько форматов описания данных на основе
XML. Самый распространенный формат получил название
RSS. Сегодня экспорт данных в формате RSS осуществляют крупнейшие порталы, включая
CNN (
http://www.cnn.com/),
BBC News (
http://www.bbc.co.uk/),
CNet News (
http://www.cnet.com/),
MSNBC (
http://www.msnbc.com/),
The Register (
http://www.theregister.com/),
Wired News (
http://www.wired.com/) и др. Аналитики отмечают, что только в 2004 году пользователи интернета по-настоящему открыли для себя возможности технологии RSS.
Сегодня для работы с данными в формате
RSS создаются новые программы, сайты и поисковые системы, которые все более востребованы пользователями. Возможно, подобные технологии и программы сумеют вскоре приоткрыть завесу над гигантской частью "скрытого" вэба.
Некоторые поисковые системы недавно предложили систему поиска по так называемым блогам (
blog=weBlog - веб-дневник). Такую возможность предоставляют, например,
Google (
http://blogsearch.google.com/) и
Яndex (
http://blogs.yandex.com/)/
Новый сервис индексирует информацию, содержащуюся не только в популярной системе интернет-публикаций
Blogger, которую Google приобрела вместе с создавшей ее компанией
Pyra в начале 2003 года, но и в других блогах, имеющих экспорт записей в формате
RSS и
Atom. База данных
Google Blog Search постоянно обновляется, однако в настоящее время в ней содержатся записи, опубликованные, преимущественно, позже июня 2005 года. В перспективе Google намерена включить в свой индекс и более старые дневники.
Аналогичную службу в декабре 2004 года запустила компания "Яндекс". Система blogs.yandex.ru индексирует все блоги и форумы, имеющие экспорт записей в формате
RSS версий 0.9x, 1.0, 2.0. Записи часто обновляемых блогов и форумов индексируются несколько раз в час, обновление базы происходит каждые 5 минут. Кстати, пока блог-поисковик "Яндекс", также как и Google Blog Search, работает в тестовом режиме.
наверьх
следующий раздел
предыдущий раздел
